The Promise of RAG: Bringing Enterprise Generative AI to Life
By grounding AI in an organization's unique expertise, Retrieval-Augmented Generation (RAG) helps enterprises overcome hurdles in deploying large language models. AI21's RAG Engine provides advanced retrieval capabilities without enterprises having to invest heavily in development and maintenance.
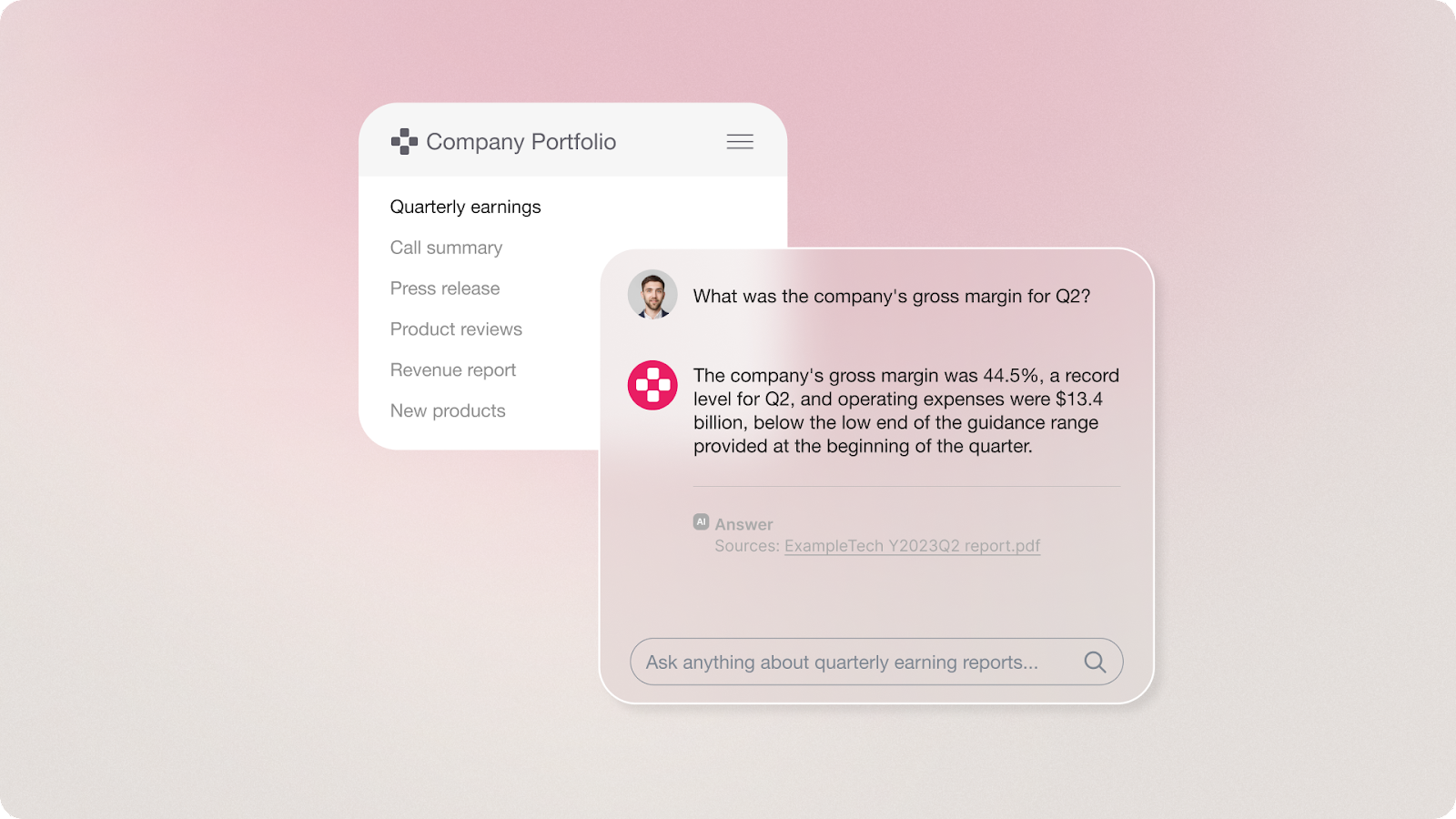
If you’ve been following generative AI and large language models in the past few months, chances are you have also heard the term Retrieval-Augmented Generation or RAG for short. Not just a buzzword, RAG shows incredible promise in overcoming hurdles in large language models (LLMs) that currently prevent adoption for enterprises in production environments.
For LLMs like Jurassic to truly solve a business problem, they need to be attuned to the unique body of knowledge that each organization has. Think of a generative AI-powered chatbot that interacts with retail bank customers. A bot powered by a general knowledge-trained LLM can broadly inform customers what a mortgage is and when it can generally be issued, but this is hardly helpful to a customer who wants to know how a mortgage is applicable to their specific circumstance. On the other hand, a chatbot using RAG understands the context: the bank’s unique mortgage policies, customer banking details, and other proprietary organizational information to provide a tailored, accurate, grounded answer to a customer’s question about a mortgage.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) integrates the deep understanding and generation capabilities that language models have, with the vast, unique knowledge of each organization. It does this by combining two processes: retrieval and augmented generation. Retrieval involves searching through documents to find relevant information that matches a user’s query or input. Augmented generation then generates text based on the retrieved information, using instruction-following large language models (LLMs) or task-specific models.
Companies across industries are experimenting with implementing RAG into their systems, recognizing its potential to significantly enhance the quality and relevance of generated content by providing up-to-date, factual information drawn from a broad range of sources within the organization. RAG gives organizations the ability to base text generation on information contained in a corpus of text, also known as grounding.
By retrieving relevant context using RAG, companies can realize many benefits in their generative AI solutions, such as:
Improving factual accuracy & minimizing risk
Generating more specific and nuanced text
Allowing for better personalization
Top RAG Use Cases in the Enterprise
RAG use cases in applications can generally be categorized into two main categories: Internal (organizational-facing) applications that are aimed at improving organizational efficiency and knowledge management and External (customer-facing) applications which focus on enhancing customer experience and engagement.
Internal RAG use cases
Internal RAG-based applications target internal stakeholders within an organization, such as employees or managers, helping them navigate and utilize the vast amount of organizational knowledge effectively. Below are just a few examples of use cases we’ve seen our customers adopt.
Employee productivity apps -Assist employees in finding and leveraging existing organizational knowledge buried across databases, emails, and documents.
Analysis assistants - Provide insights to employees through document summarization or Q&A by retrieving and synthesizing internal research documentations, such as financial reports, research studies, clinical trials, market trends, competitor analysis, and customer feedback.
Employee training tools - Help onboard and educate new employees with tools that locate relevant information.
External RAG use cases
External RAG-based applications focus on enhancing the customer experience and engagement, retrieving secured organizational data on behalf of customers or clients.
Customer support chatbots - Enhance customer support by providing accurate, context-rich responses to customer queries, based on specific user information and organizational documents like help center content & product overviews.
Public-facing Q&A systems - Address customer inquiries and tickets with accurate and detailed answers grounded in your organization’s proprietary knowledge. For example, implemented in a retail website, such a system would address questions about specific products, shipping policies, and more. An important feature is that the system won’t respond to any questions whose answers aren’t in the associated documents. This is critical for mitigating risk and ensuring compliance especially for privacy-sensitive enterprises.
How Does It Work?
As its name implies, RAG consists of two main steps, retrieval and augmented generation.
Retrieval
Retrieval is the process of searching through organizational documents to find relevant information that matches a user's query or input. Retrieval techniques range from simple keyword matching to more complex algorithms that analyze document relevance and user context. The effectiveness of a retrieval system is measured by its ability to provide accurate, relevant, and timely information, meeting the precise needs of its users.
Semantic Search
One of the more advanced approaches on the retrieval spectrum is semantic search. Semantic search is the technique of understanding the underlying intent of a search query to retrieve relevant results from a corpus of documents. Beyond simple keyword matching, it matches the semantic meaningwith the help of machine learning and AI technologies. For example, semantic search would know to closely match the terms “cute kittens” to “fluffy felines”, even though there is no literal word match.
There are several steps required to build a semantic search system, involving different processes:
Embedding (vectors): An embedding model transforms text from indexed documents and a query into fixed-size vectors (a list of numbers), capturing their semantic meanings in a high-dimensional space. This allows computers to semantically search for relevant information in a user query.
Vector Database: Embeddings are typically stored in a dedicated vector database (provided by vendors such as Pinecone or Weaviate), which can search through vectors to find the most similar results for a user query. Vector databases are designed to be highly scalable and efficient when searching through billions of vectors.
Document chunking: To improve vector search and retrieval, it is recommended to first segment large documents into smaller chunks (around a paragraph each) by topic. This will allow you to create vectors for each chunk, rather than for the entire document, enabling even more fine-grained vector search. It also allows you to locate specific relevant text from your source documents, and pass it to a language model for text generation.
Augmented generation
Once organizational information is retrieved through semantic search, general purpose LLMs like Jurassic can then generate a response according to the prompt it was given (such as “summarize the content”, or “answer an end user question”). Task-specific models such as Contextual Answers, designed for RAG-based Q&A, can also be used out-of-the-box to craft an answer to a question without any prompt engineering needed.
Building a RAG solution is easy. Building a great one is not.
Although retrieval tools and knowledge are widely available, moving from proof of concept (POC) to production for enterprises is harder than it seems. No matter how tech savvy your organization may be, building and maintaining a multi-document retrieval system is complex and comes with many difficulties:
Optimizing chunking and embedding processes and models in order to achieve high-quality retrieval results
Supporting various file types (e.g. PDF, DOCX) and correctly extracting information from each file type (e.g. complex tables)
Creating an effective context based on the retrieved chunks to optimize generation output
Scalability when indexing and retrieving a large number of documents stored in one or more organizational data sources, common for production workloads. Organizational data can reside in different systems - file management systems (such as Google Drive or OneDrive), file storage (such as S3 or Google Storage), writing platforms (such as Confluence or Notion), customer support systems (such as Intercom or Zendesk) and others. Depending on the use case, organizations will need to create an ingestion pipeline to index documents from one or more systems.
Keeping synchronization between original documents and indexed documents as content in documents changes over time.
Adhering to organizational user and group permissions when retrieving documents.
Legal, security and privacy concerns affecting data location. Building a RAG system must comply with relevant regulations such as GDPR, which may dictate data persistence, the necessity of on-premise or Virtual Private Cloud (VPC) storage, and restrictions on geographical data transfer and storage.
While individual tools for creating retrieval solutions are becoming more accessible and various new retrieval frameworks are emerging, developing a robust semantic search system remains a significant challenge for organizations.
AI21’s RAG Engine (Or, Why Reinvent the Wheel?)
AI21's RAG Engine offers enterprises an all-in-one solution for implementing Retrieval-Augmented Generation. RAG Engine allows companies to upload their organizational documents, retrieve the most relevant information for a given query, and connect that context to a large language model like Jurassic-2 or a task-specific model to generate text. RAG Engine is conveniently packaged and accessible via an API endpoint.
It also adeptly addresses implementation challenges, offering a RAG solution built for production use cases in the enterprise. It lets you efficiently integrate advanced retrieval capabilities without having to invest heavily in development and maintenance. RAG Engine contains built-in mechanisms for every step of the way, including document extraction, chunking, embeddings, vector storage and retrieval.
We’ve used our experience helping thousands of global enterprises, including leaders in banking, life sciences and retail, to create the optimal retrieval solution. We believe organizations can greatly benefit from out-of-the-box solutions that streamline the process and reduce technical overhead so they can focus on their core business.
Seamless integration between retrieval and generation - RAG Engine automatically integrates with many of our task-specific models, so you can surface search results or provide a grounded answer to a query based on your organizational data – all within a single API call. You can also connect RAG Engine with a foundation model like Jurassic – and use Semantic Search results within a prompt.
Built-in data source integration - You can integrate your organization’s data sources, such as Google Drive, Amazon S3, and others, to automatically sync documents with RAG Engine. To enable data source integration, contact us.
Supports various file formats and data types - Using our document extraction capabilities, ensure high-quality retrieval across file types like PDFs and DOCX files, while adeptly handling complex structures such as tables.
Builds effective contexts for language models - Our Embeddings and Text Segmentation models use advanced semantic and algorithmic logic to create the optimal context from retrieval results, significantly enhancing the accuracy and relevance of generated text.
Easy maintenance - RAG Engine maintains synchronization between original and indexed documents as they evolve, ensuring up-to-date information retrieval.
Secure and appropriate access to documents - Adhere to organizational user and group permissions with a comprehensive approach that addresses the intricate needs of document management in modern, data-intensive environments.
RAG Engine gives enterprises a robust managed retrieval system that integrates production-grade models as key components. However, if you prefer the flexibility to build your own retrieval solution, you can access these task-specific models, optimized to excel in their respective task.
Semantic Search model - Retrieves the most relevant chunks (segments) from text based on the intent and contextual meaning of a query
Text Segmentation model - Breaks down text into chunks (segments) with distinct topics using advanced semantic logic
Embeddings model - Uses advanced techniques to create contextual embeddings, significantly enhancing the accuracy and relevance of search results
Document Extraction model - Filters and extracts relevant information from large volumes of data, including PDF and DOCX files with complex tables
Looking Ahead
Many enterprises are looking to move beyond LLM experimentation to adoption by implementing RAG-based solutions. RAG holds a lot of promise for overcoming reliability challenges through grounding and deep understanding of a given context. Despite the plethora and availability of knowledge and tools, building a RAG system fit for enterprise production needs is not as simple as it seems. Organizations must build, optimize and continuously maintain numerous processes of the RAG pipeline, including chunking and embedding, in order to produce an optimal context that can be integrated with LLM generation capabilities.
No matter how technologically adept your organization is, building a RAG solution is costly in time and resources. With customers from the top banks, analytics, healthcare and retail companies utilizing our RAG Engine, we can help.
In August 2021 we released Jurassic-1, a 178B-parameter autoregressive language model. We’re thankful for the reception it got – over 10,000 developers signed up, and hundreds of commercial applications are in various stages of development. Mega models such as Jurassic-1, GPT-3 and others are indeed amazing, and open up exciting opportunities. But these models are also inherently limited. They can’t access your company database, don’t have access to current information (for example, latest COVID numbers or dollar-euro exchange rate), can’t reason (for example, their arithmetic capabilities don’t come close to that of an HP calculator from the 1970s), and are prohibitively expensive to update. A MRKL system such as Jurassic-X enjoys all the advantages of mega language models, with none of these disadvantages. Here’s how it works.
Compositive multi-expert problem: the list of “Green energy companies” is routed to Wiki API, “last month” dates are extracted from the calendar and “share prices” from the database. The “largest increase“ is computed by the calculator and finally, the answer is formatted by the language model.
There are of course many details and challenges in making all this work - training the discrete experts, smoothing the interface between them and the neural network, routing among the different modules, and more. To get a deeper sense for MRKL systems, how they fit in the technology landscape, and some of the technical challenges in implementing them, see our MRKL paper. For a deeper technical look at how to handle one of the implementation challenges, namely avoiding model explosion, see our paper on leveraging frozen mega LMs.
A further look at the advantages of Jurassic-X
Even without diving into technical details, it’s easy to get a sense for the advantages of Jurassic-X. Here are some of the capabilities it offers, and how these can be used for practical applications.
Reading and updating your database in free language
Language models are closed boxes which you can use, but not change. However, in many practical cases you would want to use the power of a language model to analyze information you possess - the supplies in your store, your company’s payroll, the grades in your school and more. Jurassic-X can connect to your databases so that you can ‘talk’ to your data to explore what you need- “Find the cheapest Shampoo that has a rosy smell”, “Which computing stock increased the most in the last week?” and more. Furthermore, our system also enables joining several databases, and has the ability to update your database using free language (see figure below).
Jurassic-X enables you to plug in YOUR company's database (inventories, salary sheets, etc.) and extract information using free language
AI-assisted text generation on current affairs
Language models can generate text, yet can not be used to create text on current affairs, because their vast knowledge (historic dates, world leaders and more) represents the world as it was when they were trained. This is clearly (and somewhat embarrassingly) demonstrated when three of the world’s leading language models (including our own Jurassic-1) still claim Donald Trump is the US president more than a year after Joe Biden was sworn into office. Jurassic-X solves this problem by simply plugging into resources such as Wikidata, providing it with continuous access to up-to-date knowledge. This opens up a new avenue for AI-assisted text generation on current affairs.
Who is the president of the United States?
T0
Donald Trump
GPT-3
Donald Trump
Jurassic-1
Donald Trump
Google
Joe Biden
Jurassic-X
Joe Biden is the 46th and current president
Jurassic-X can assist in text generation on up-to-date events by combining a powerful language model with access to Wikidata
Performing math operations
A 6 year old child learns math from rules, not only by memorizing examples. In contrast, language models are designed to learn from examples, and consequently are able to solve very basic math like 1-, 2-, and possibly 3- digit addition, but struggle with anything more complex. With increased training time, better data and larger models, the performance will improve, but will not reach the robustness of an HP calculator from the 1970s. Jurassic-X takes a different approach and calls upon a calculator whenever a math problem is identified by the router. The problem can be phrased in natural language and is converted by the language model to the format required by the calculator (numbers and math operations). The computation is performed and the answer is converted back into free language. Importantly (see example below) the process is made transparent to the user by revealing the computation performed, thus increasing the trust in the system. In contrast, language models provide answers which might seem reasonable, but are wrong, making them impractical to use.
The company had 655400 shares which they divided equally among 94 employees. How many did each employee get?
T0
94 employees.
GPT-3
Each employee got 7000 stocks
Jurassic-1
1.5
Google
(No answer provided)
Jurassic-X
6972.3 X= 655400/94
Jurassic-X can answer non-trivial math operations which are phrased in natural language, made possible by the combination of a language model and a calculator
Compositionality
Solving simple questions might require multiple steps, for example - “Do more people live in Tel Aviv or in Berlin?” requires answering: i. What is the population of Tel-Aviv? ii. What is the population of Berlin? iii. Which is larger? This is a highly non-trivial process for a language model, and language models fail to answer this question (see example). Moreover, the user can’t know the process leading to the answers, hence is unable to trust them. Jurassic-X can decompose such problems into the basic questions, route each to the relevant expert, and put together an answer in free language. Importantly, Jurassic-X not only provides the correct answer but also displays the steps taken to reach it, increasing the trust in the system.
Do more people live in Tel Aviv or in Berlin?
T0
Berlin
GPT-3
There are more people living in Tel Aviv than in Berlin.
Jurassic-1
Berlin and Tel Aviv are roughly the same size
Google
(First hit is a comparison between Tel Aviv and Berlin)
Jurassic-X
More people live in Berlin than in Tel-Aviv
[‘Return population of Tel Aviv’; Return population of Berlin’; Return which is bigger between #1 and #2’] Step 1: Population of Tel Aviv. Result - 451523. Step 1: Population of Berlin. Result - 3664088. Step 3: Which is bigger, #1 or #2. Result - Berlin.
Jurassic-X breaks down compositional questions, answers the basic sub-questions, and puts together the answer. Importantly, this process is transparent to the user greatly increasing the trust in the system
Dynamic information (like weather and currency exchange rates)
Certain types of information change continuously - weather, currency exchange rates, share values and more. Such information will never be captured by language models, yet can easily be handled by Jurassic-X by integrating it with a reliable source of information. We performed a proof-of-concept on two such features - weather and currency exchange rates, and the design enables quick integration with more sources to solve your use-case. Weather - a loosely phrased question about the weather elicits an answer from all language models, where language models always return the same answer, regardless of when the question was asked (funny, right?), while Jurassic-X provides an answer based on the actual weather prediction.
I’m going to be in New-York in 3 days. Should I pack my umbrella?
T0
No
GPT-3
Yes, you should pack your umbrella.
Jurassic-1
Yes, you should. The weather forecast is rain.
Google
(Links to weather websites)
Jurassic-X
Yes, you should pack your umbrella, because in New York in 3 days there will be broken clouds and the temperature will be -2 degrees.
Currency exchange rates change much faster than weather predictions, yet the Jurassic-X concept - a language model connected to a reliable source of information - easily solves this problem as well.
How much Moroccan money will I get for 100 bucks?
T0
125 dirhams
GPT-3
100 moroccan dirhams is about 27$.
Jurassic-1
How much is 100 dollars in moroccan money?
Google
100 dirhams = 10.75 dollars
Jurassic-X
100 USD = 934.003 MAD
Jurassic-X combines a language model with access to APIs with continuously changing information. This is demonstrated for weather forecasts and currency exchange rates, and can easily be extended to other information sources
Transparency and trust
Transparency is a critical element that is lacking in language models, preventing a much wider adoption of these models. This lack of transparency is demonstrated by the answers to the question - “Was Clinton ever elected as president of the United States?”. The answer, of course, depends on which Clinton you have in mind, which is only made clear by Jurassic-X that has a component for disambiguation. More examples of Jurassic-X’s transparency were demonstrated above - displaying the math operation performed to the user, and the answer to the simple sub-questions in the multi-step setting.
Was Clinton ever elected president of the United States?
T0
Yes
GPT-3
No, Clinton was never elected as president of the United States.
Jurassic-1
No
Google
Clinton was elected president in the 1992 presidential elections…
Jurassic-X
Bill Clinton was elected president.
Jurassic-X is designed to be more transparent by displaying which expert answered which part of the question, and by presenting the intermediate steps taken and not just the black-box response
Your Turn
That's it, you get the picture. The use cases above give you a sense for some things you could do with Jurassic-X, but now it's your turn. A MRKL system such as Jurassic-X is as flexible as your imagination. What do you want to accomplish? Contact us for early access
Thank you!
Your submission has been received!
Oops! Something went wrong while submitting the form.










.png)
.png)
.png)